Jetzt, in Zeiten von Corona, bekommt man ständig Statistiken zu sehen und damit werden alle möglichen Dinge erklärt. Jedoch lautet ein Sprichwort: »Man kann mit Statistiken alles zeigen – sogar das Gegenteil.« Statistik, als Methodik, dient dazu eine Hypothese, die vor der Ermittlung der Zahlen aufgestellt wird, zu bestätigen oder zu widerlegen. Das was heute oft mit den Mitteln der Statistik getan wird, ist eine Datenanalyse, also ein Suchen nach Zusammenhängen und Erkenntnissen in den Daten.
Das Problem einer Statistik sind selten die Zahlen, vielmehr ist ihre Deutung mit Unsicherheit behaftet und die Quelle von Fehlern. Es gibt zwar auch wissenschaftliche Publikationen, deren Zahlen nicht reproduzierbar sind (und erfunden seien könnten), aber das ist seltener das Problem. Viel wichtiger ist immer die Frage, wie die Zahlen zu Stande kamen, also was sie wirklich aussagen, und wie die Zahlen im Vergleich mit anderen Ergebnissen einzuordnen sind. Gern werden Zahlen präsentiert, die groß und beeindruckend wirken, aber im Vergleich gar nicht so bedeutsam sind. Oder Zahlen werden gern verwendet, um etwas zu suggerieren, das gar nicht in ihnen steckt.
Die Bedeutung und Qualität der Zahlen – Was wurde da gezählt?
Nimmt man sich zum Beispiel die Anzahl der Neuinfektionen mit Covid-19 in Deutschland pro Tag so sieht man zwar schwankende Werte, aber man könnte darin auch Tendenzen erkennen. Zu dem Diagramm in der Wikipedia ist aber eine wichtige Anmerkung gemacht worden:
Gesamtplus der Fälle zum Vortag verteilt sich auf verschiedene Tage aufgrund des Übermittlungsprozesses. Beispielsweise wurden am 27. März 2020 5.780 Fälle neu übermittelt. Davon wurden 1.840 am 26. März gemeldet, 2.452 am 25. März, 747 am 24. März usw.
Die Zahl, die jeden Tag in den Nachrichten verkündet wird, die Anzahl der Neuinfektionen im Vergleich zum Vortag sagt nichts darüber aus, wie viele neue Infektionen es am Vortag gab, sondern wie viele neue Infektionen am Vortag (für die gesamten Tage zuvor) bekannt geworden sind. Das ist ein kleines, sprachliches Detail, aber es kann zu einer ganz anderen Deutung führen.
Auf der Übersichtsseite zu Covid-19 des RKIs sind im Diagramm rechts unten wiederum die Fälle den entsprechenden Tagen zugeordnet und man sieht, dass die »neu berichteten Fälle« sich auf mehrere Tage in der Vergangenheit verteilen. Wie viele Fälle wirklich an einem Tag gemeldet wurden, zeigt sich also erst nach mehreren Tagen.
Allerdings ist auch dort im Haftungsausschluss (Disclaimer) zu lesen:
Für die Darstellung der neuübermittelten Fälle pro Tag wird das Meldedatum verwendet – das Datum, an dem das lokale Gesundheitsamt Kenntnis über den Fall erlangt und ihn elektronisch erfasst hat.
Zwischen der Meldung durch die Ärzte und Labore an das Gesundheitsamt und der Übermittlung der Fälle an die zuständigen Landesbehörden und das RKI können einige Tage vergehen (Melde- und Übermittlungsverzug).
Diese Zahlen sagen also auch nichts darüber aus, wie viele neue Infektionen es an einem Tag gegeben hat, sondern nur darüber, wann das Ergebnis dem Gesundheitsamt gemeldet wurde. Von drei Bekannten, die auf Sars-Cov-2 getestet wurden, weiß ich, dass ihnen das Ergebnis erst drei Tage nach der Probenentnahme mitgeteilt wurde, so dass zu vermuten ist, dass das gesamte Diagramm um zwei Tage verschoben ist.
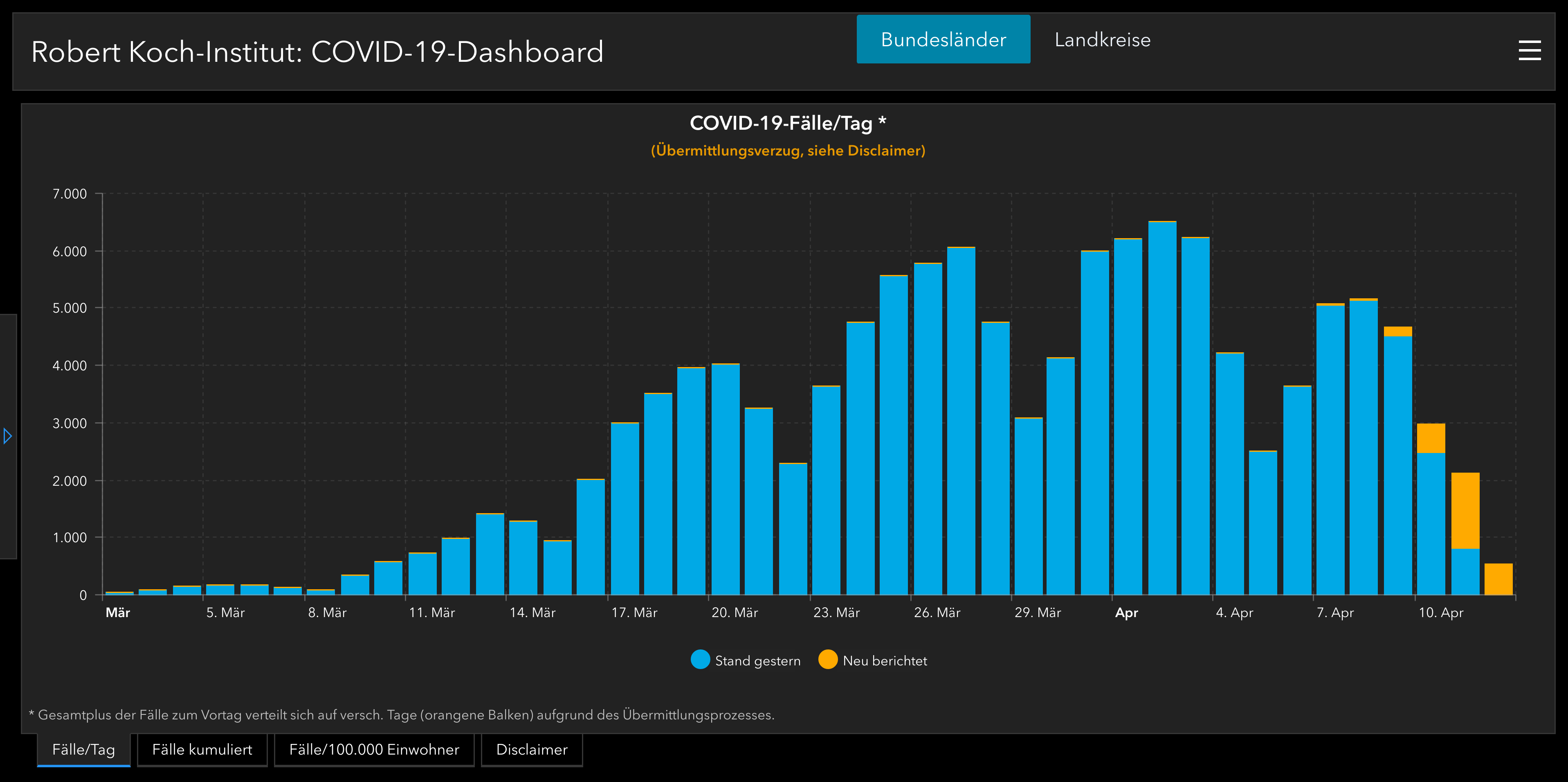
Auffällig an dem Diagramm sind die Wellen, die immer wieder ein Absinken der Infektionen am Sonnabend und Sonntag suggerieren. Da es unwahrscheinlich ist, dass die Sars-Cov-2-Viren einen Tarifvertrag abgeschlossen haben, der ihre Verbreitungstätigkeit auf die deutschen Werktage beschränkt, sieht man hier viel mehr, wann die Labore und Gesundheitsämter arbeiten.
Um also einen Trend ablesen zu können, ist es günstiger, jeweils die Zahlen der Wochentage miteinander zu vergleichen. Ein ähnliches Prinzip ist von den Arbeitsmarktstatistiken bekannt: Dort wird auch der Vergleich zum selben Monat des Vorjahres gezogen, um saisonale Einflüsse ausschließen. Daneben gibt es auch sogenannte saisonbereinigte Zahlen. Bei diesen wird versucht, mathematisch den saisonbedingten Einfluss zu bestimmen und die Zahlen dementsprechend anzupassen, so dass man diese normierten Zahlen mit den normierten Zahlen des Vormonats vergleichen kann. Ein weiteres Beispiel für eine solche Bereinigung ist die Inflationsbereinigung, die zum Beispiel bei Preisen genutzt wird und als sogenannte Kaufkraft den Preis eines Brotes 1950 mit dem heute vergleichbar macht.
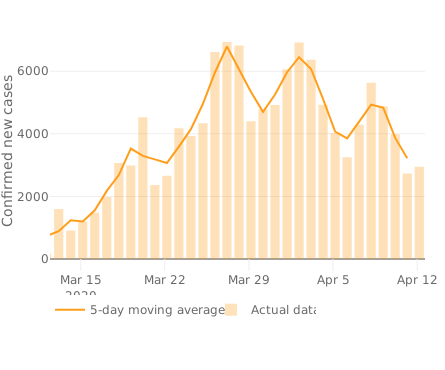
Für solche Bereinigungen muss man ein gutes Wissen über die Abläufe haben, das im Fall der Corona-Krise nicht vorhanden ist – bzw. habe ich es bisher noch nichts dergleichen gesehen. Eine andere Methode zum Ausgleich unterschiedlicher Rahmenbedingungen ist daher ein Mittelwert. So hat zum Beispiel die Johns Hopkins Universität in ihrem Diagramm einen gleitenden Mittelwert (mit jeweils zwei Tagen zuvor und danach) eingezeichnet. Dieser verläuft zwar auch in Wellen, aber diese sind abgeflacht (»geglättet«), so dass Sonntage und Mittwoche nicht so extrem voneinander abweichen und eher eine Aussage zum Trend möglich ist.
Aufgrund der oben beschriebenen (Nach-)Meldungen der Ergebnisse kann es auch zu Spitzen, sogenannten Ausreißern, kommen. So hat zum Beispiel Frankreich am 3. April über 17.000 Infektionen von vorangegangenen Tagen und Wochen gemeldet, die im Diagramm herausstechen:
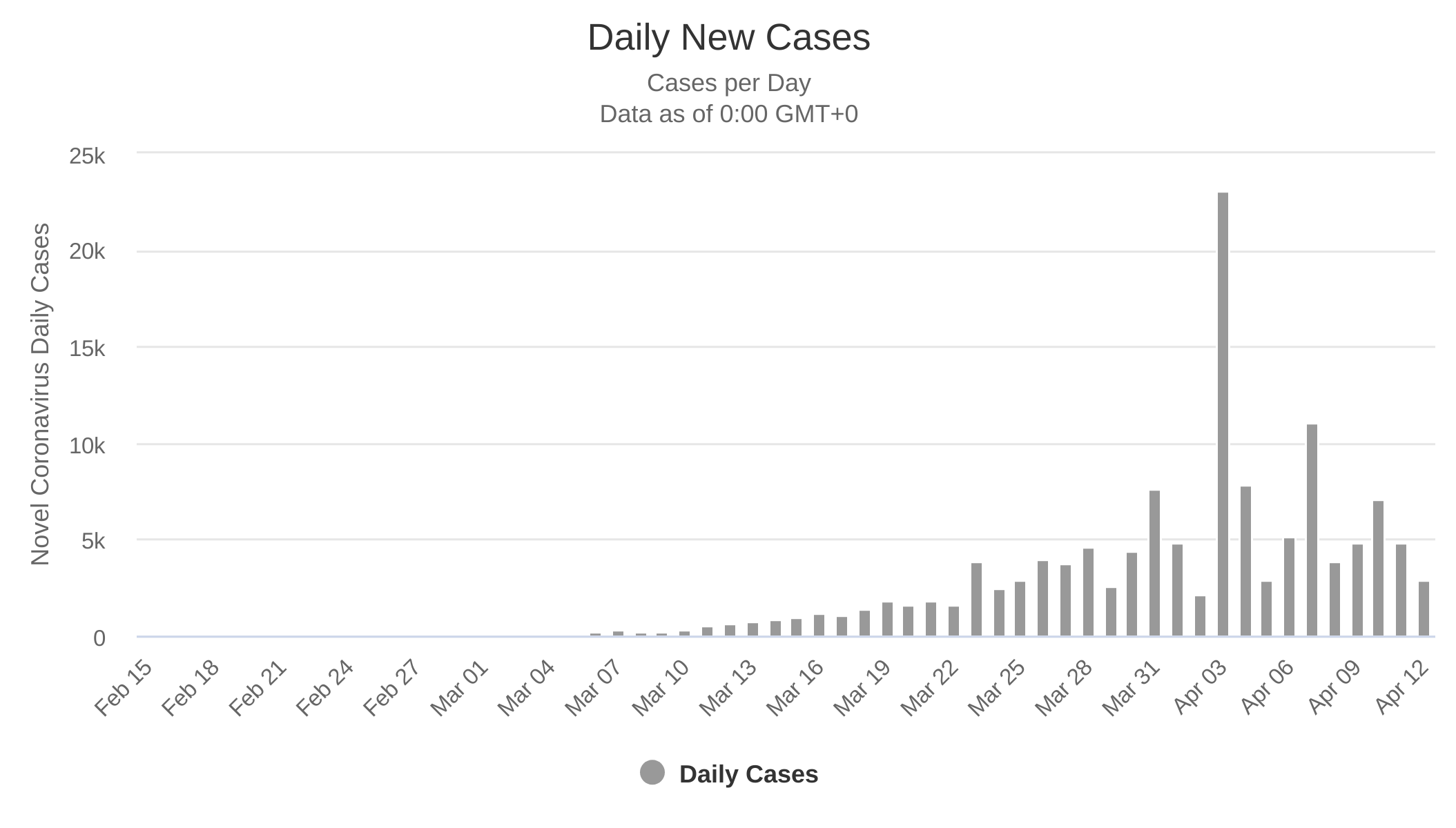
Solche Vorkommnisse sollten jedoch nicht zur Panik veranlassen, sondern deuten stark auf einen Mangel an Güte bei den Ermittlungen der Zahlen hin.
Wenn man noch weiter nach der Aussagekraft der Daten sucht, so kommt man für die deutschen Zahlen schnell auf Feinheiten wie:
die Infektions- und Sterbezahlen beziehen sich auf den Diagnoseort und nicht den Wohnort. Dabei werden Orte mit Krankenhäusern bedingt durch die Sache stärker bewertet als Orte ohne. Vergleiche auf Kreisebene sind also mit Vorsicht zu betrachten.
für Patienten die versterben gibt es einen Unterschied, ob sie mit oder an Sars-Cov-2 verstorben sind, also ob der Virus nur eine Begleiterscheinung oder ursächlich für den Tod war. Bei keiner anderen erkennbaren Todesursache ist es wahrscheinlich, dass der Virus den Tod herbeigeführt hat. Das Zählen von einzelnen Toten ist also auch nicht so exakt, wie es suggeriert wird.
die Anzahl der Grippetoten werden geschätzt. Man ermittelt durch mathematische Modelle, wie viele Tote in dem Zeitraum hätten sterben sollen und bildet die Differenz zu den tatsächlichen Fällen. Diese Fallzahlen sind also auch nicht exakt und geben nur grob eine Orientierung.
Eine anderes anschauliches Problem bei der Ermittlung der Daten hatten wir bei den Download-Zahlen des Datenkanals: Naiv haben wir anfangs aus dem Protokoll des Webservers die Anzahl der Abfragen genommen. Dabei kamen jedoch solch große Zahlen heraus, dass wir diese selbst angezweifelt haben. So sind wir auf das Problem gestoßen, dass einige Programme die Dateien stückweise abrufen und somit häufiger anfragen, als eigentlich zu erwarten ist. Wir haben uns am Ende für die Kennzahl abgerufene Datenmenge pro Dateigröße entschieden.
Diese Größe ist zwar auch nur eine Näherung für das Interesse an unserem Podcast, aber es lässt über die Zeit hinweg eine Aussage über den Trend zu. Jedoch zeigt dieses Beispiel, dass Klickzahlen und echtes Interesse für Webseiten schwer zu ermitteln sind und solche Schlüsse von der Anzahl der Seitenaufrufe zu den Nutzerzahlen schwierig sind – weshalb es auch so viele Tracker und Tracking-Methoden gibt.
Im Vergleich – Ist das nun viel oder wenig?
TODO: Einarbeiten: Mit der Angabe »jemand wiegt 75 kg« kann man keine Aussage darüber treffen, ob derjenige schlank oder dick aussieht. Aus dem Gewicht, lässt sich nur in Verbindung mit der Körpergröße auf diese Eigenschaft schließen. Für einen Menschen von 1,60 m Größe sind 75 kg viel, bei 1,80 m hingegen nicht.
Wenn man Zahlen in die Hand bekommt, muss man auch immer über deren Relevanz und Bedeutung nachdenken. Wenn in einem Spiel 1000 Gewinne möglich sind, klingt dies erst einmal viel. Sind aber auch 10.000 Nieten in dem Spiel, so mag man seinen Einsatz überdenken.
Aber nicht nur der Vergleich innerhalb des Systems ist wichtig, sondern auch der Vergleich zu anderen Systemen. Ein Einsatz bei einem Spiel mit 100 Gewinnen bei 200 Nieten erscheint sinnvoller. Bei klinischen Studien zur Wirksamkeit von Medikamenten benutzt man deshalb eine sogenannte Kontrollgruppe oder Referenzprobe, also einen zweiten, möglichst gleichen Aufbau für einen Vergleich. Und in der Wortwahl »möglichst gleich« steckt schon der Hinweis auf ein weiteres Problem bei Vergleichen: Die Referenzprobe kann sich strukturell von der Messprobe unterscheiden und damit die Vergleichbarkeit erschweren. Es werden dann, wie man so landläufig sagt, Äpfel mit Birnen verglichen.
Vergleiche sollten also in zwei Richtungen unternommen werden: (1) wie ist die Bedeutung für das Gesamtsystem – relative und absolute Werte betrachten – und (2) wie ist das Ergebnis im Vergleich mit anderen Ergebnisse einzuordnen.
Für die Covid-19-Zahlen gibt es viele Vergleichsmöglichkeiten, um die Zahlen einzuordnen, also in Relation zu stellen:
Die absoluten Zahlen sind über Ländergrenzen hinweg nicht vergleichbar. Die Gesamtbevölkerung der USA ist zum Beispiel größer als die von Deutschland und ebenso leben in Bayern mehr Menschen als in Thüringen, weshalb in den USA und in Bayern mehr Infektionsfälle und Tote zu erwarten sind. Das ist ein richtiger Apfel-Birnen-Vergleich. Besser wäre es, die Anzahl der Fälle bezogen auf die Gesamtbevölkerung zu bestimmen.
Bei Worldometer gibt es eine wunderbare Tabelle, die sehr gut die Daten aufbereitet. In den Spalten »Tot Cases/1M pop« und »Deaths/1M pop« sind genau die Verhältnisse zur Gesamtanzahl der überhaupt möglichen Fälle dargestellt.
Am 16. April lagen die USA dort bei den Infektionsfällen hinter Frankreich und vor Portugal und Deutschland. Da die Fallzahlen aber sehr stark davon abhängen, wie viele Menschen getestet werden, ist die Zahl mit rund 1900 Infizierten pro 1 Million Einwohner auch mit Vorsicht zu betrachten und veränderte sich auch in den letzten Tagen. Betrachtet man die Toten so gibt es in den USA weniger Tote als in Schweden und mehr als in Portugal und Deutschland. So bedrohlich, wie die absoluten Zahlen in den Diagrammen wirken, sind sie es im Vergleich dann gar nicht.
Auf dem Dashboard des RKIs gibt es rechts eine Analyse der Fälle nach Altersgruppe und Geschlecht. Diese gibt es als absolute Anzahl und als relativ zu 100.000 Einwohnern. Während absolut gesehen die meisten Fälle bei Personen zwischen 35 und 59 Jahren auftreten, sind es bezogen auf die überhaupt möglichen Gesamtfälle die über 80-Jährigen mit den meisten Infektionen. Wieder ergeben absolut und relativ andere Aussagen.
Man kann aber nicht nur die selben Ereignisse unter unterschiedlichen Bedingungen vergleichen, sondern auch Vergleiche zu ähnlichen Ereignissen ziehen. Sind denn 3 800 Tote viel oder wenig bei einer Virusinfektion? Interessant ist zum Beispiel die Anzahl der Toten durch die Grippe in den vergangenen Jahren zu betrachten.
Ein Umstand, der mir auch bis jetzt nicht bekannt war, ist, dass wir alle paar Jahre um die 20.000 zusätzliche Tote durch die Grippe haben. In der Saison 2008/09: 18.800, 2012/13: 20.700, 2014/15: 21.300, 216/17: 22.900, 2017/18: 25.100. (Quelle: Saisonbericht 2018 vom RKI auf Seite 47)
Spannend an dieser Tabelle ist: Schaut man sich die Spitzenwerte an, so sieht man, dass diese immer größer und häufiger werden. Was wäre also eine gute Schlagzeile »Panik: Die Grippe wird immer tödlicher«. Aber schaut man in den Saisonbericht 2014 auf Seite 44, so sieht man, dass es auch in den 1990er Jahren viele Grippetote gab: 24.900 (1995/96), 15.200 (1998/99) und 12.700 (1999/2000).
Interessant wird also der Influenza-Saisonbericht 2021, in dem die geschätzten Grippetoten in der Saison 2019/20 veröffentlicht werden.
Datenanalyse bei Worldometer am 16. April
Leider hat Worldometer recht restriktiv klingende Nutzungsbestimmungen, weshalb ich lieber keine Bilder hier bringe, aber meine Beobachtungen zur Datentabelle kann ich hier äußern:
Wenn man die Anzahl der Tests pro 1 Million Einwohner betrachtet, liefern Island (10 %), die Vereinigten Arabischen Emirate (8 %) und Luxemburg (5 %) die besten Zahlen. In Luxemburg und Island liegt die Infektionsrate bei 0,5 % und in VAE bei 0,05 %. Den Unterschied würde ich in den unterschiedlichen Klimazonen sehen. Innerhalb Europas liegt die Infektionsrate zwischen 0,5 % und 0,1 % bei den Ländern, die mehr als 20.000 Test bezogen auf 1 Million Einwohnern durchgeführt haben.
Bei einer Sortierung nach den Fällen pro 1 Million Einwohner haben in Europa Luxemburg (0,5 %), Island (0,5 %) und Spanien (0,4 %) die meisten Fälle. Die USA liegt mit 0,2 % im Mittelfeld. Aber die Fälle der Infektionen ist unsicher: Wo nicht viel gemessen wird, kann auch nichts gefunden werden. Hier könnte eine spätere repräsentative Antigen-Untersuchung der Bevölkerung bessere Zahlen zu den Infektionen und der Durchseuchung liefern.
Am besten geeignet zur Analyse finde ich daher die Anzahl der Todesfälle auf 1 Million Einwohner, weil die Toten sehr sicher entdeckt und gezählt werden. Bei den Toten ragen in Europa vor allem Belgien (0,042 %), Spanien (0,041 %), Italien (0,037 %) und Frankreich (0,026 %) mit über 200 Toten auf 1 Million Einwohner heraus.
Deutschland liegt im Vergleich der Todeszahlen mit 46 von 1 Million bei rund einem Achtel der Fälle von Italien – ein völlig anderes Bild als es die Diagramme der absoluten Zahlen vermitteln. Überraschend ist, dass Belgien so viele Tote hat (dort wird fast jeder Verstorbene in einem Heim als Corona-Toter gezählt), doppelt so viele wie die Niederlande und fast das Vierfache von Luxemburg. Auffällig ist auch, dass Spanien fast sieben mal so viele Tote wie Portugal hat.
Hingegen haben die Länder Tschechien (16 bei 1,4 % Tests), Finnland (14 bei 0,9 % Tests), Norwegen (28 bei 2,4 % Tests) und Slowenien (29 bei 1,8 % Test) weniger Fälle als Deutschland (46 bei 2,1 % Tests). In einigen Wochen werden sich diese Zahlen wahrscheinlich auch stabilisieren und es wird sich zeigen, welche Länder (aus welchen Gründen auch immer) besser das Virus überstanden haben als andere.
Meine Einschätzung zur Covid-19-Datenanalyse
Die täglichen Fallzahlen, wie sie in den Medien verkündet und in der Wikipedia dargestellt sind, kann man fast nicht gebrauchen. Das was man am treffsichersten daran ablesen kann, sind die deutschen Wochen- und Arbeitstage.
Die Vergleiche der absoluten Fallzahlen, wie sie die Zeit oder die Johns-Hopkins-Universität in ihren Diagrammen darstellen, sind totaler Murks und von geringer Aussagekraft und erzeugen nur Unsicherheit.
Die meiste Transparenz bietet die Tabelle bei Worldometer. Diese bietet den Vergleich der verschiedenen Zahlen für die Länder und die Relation zu einer Gesamtmenge.
Deutlich geworden an dem riesigen Datenwust ist: Datenanalyse ist nicht leicht und man muss immer aufpassen, was für Zahlen man vor sich hat. Deshalb stelle man sich bei einer Statistik (vor allem wenn sie emotional aufwühlend wirkt) immer die Fragen:
- Wie wurden die Daten ermittelt und sagen sie wirklich das aus, was suggeriert wird?
- Welche anderen Faktoren könnten die Ergebnisse beeinflusst haben?
- Sind die Vergleiche, die gezogen werden, brauchbar für eine Aussage?
- Gibt es andere Statistiken, um die vorliegende Einzuordnen?
Und auch für meine Analyse hier gilt: Nachdenken und hinterfragen. Ich werde sicher nicht die perfekte Analyse geliefert haben, aber hoffe doch, eine Anleitung zum Nachdenken gegeben zu haben.
Fazit
Ich persönlich sehe anhand der verfügbaren Zahlen keinen Grund zur Panik in Deutschland. Ich finde daher verwerflich, wie in den Medien mit den Zahlen umgegangen wird und diese sensationsheischend präsentiert werden.
Verbesserungswürdig finde ich die Übermittlungswege zum RKI und die Veröffentlichung dieser Daten. Dass teilweise Fälle erst nach Wochen (14 Neuinfektionen am 27. 3. veröffentlicht am 16. 4.) beim RKI in die Statistik einfließen, kann im Zeitalter des Internets nicht sein, und dass Zeitungen oder die Johns-Hopkins-Universität »ihre Quellen« haben und bei den Gesundheitsämtern anrufen, um die Zahlen schneller zu bekommen, sollte nicht passieren, um abweichende Meldungen, wie sie gerade kursieren, zu vermeiden.
Die Gesundheitsämter sollten ein Webportal unterhalten, zu dem alle Ärzte und Labore einen Zugang inklusive einer API für ihre Programme haben und dort tragen diese ihre Informationen ein. Eine tagesaktuelle Veröffentlichung der Zahlen halte ich für den richtigen Weg, aber die Gesundheitsämter sollten ihre Zahlen über ihre eigene Webseite veröffentlichen und auf diese Daten greifen dann das RKI, die Bevölkerung und die Medien zu.